
파이썬으로 다양한 활동을 할 수 있는데 오늘은 그 중에서 웹 크롤링하는 방법에 대해 알아보려고 한다. 웹 크롤링이란 어떤 URL에서 하이퍼링크를 분류하고 원하는 데이터를 찾아내 DB에 저장하는 것이다.
목차
1. requests 모듈 설치
2. bs4 모듈 설치
3. 크롤링 영역 찾기
4. 코드 작성
1. requests 모듈 설치
pip install requests
명령 프롬프트를 실행시켜 위의 명령어를 입력하면 설치가 진행된다. requests 모듈은 HTTP 요청을 보내는 모듈이다. 원하는 URL에 접속하여 해당 인터넷 페이지에 있는 HTML 코드를 가져오고 그 코드 중에서 원하는 내용만 스크래핑할 수 있도록 도와준다. 아나콘다를 설치한 경우에는 기본적으로 설치되어 있다.
https://pypi.org/project/requests/
requests
Python HTTP for Humans.
pypi.org
2. bs4 모듈 설치
pip install bs4
명령 프롬프트를 실행시켜 위의 명령어를 입력하면 설치가 진행된다. bs4 모듈은 HTML 코드를 비슷한 데이터끼리 나눠준다. 이걸 파싱(Parsing)이라고 한다. 개발자는 bs4 모듈이 파싱 해놓은 데이터 중에서 원하는 데이터만을 가져와 유용하게 사용할 수 있다. 아나콘다를 설치한 경우에는 기본적으로 설치되어 있다.
https://pypi.org/project/beautifulsoup4/
beautifulsoup4
Screen-scraping library
pypi.org
3. 크롤링 영역 찾기
네이버 증권
국내 해외 증시 지수, 시장지표, 뉴스, 증권사 리서치 등 제공
finance.naver.com
사용자가 데이터를 가져오고 싶은 인터넷 사이트를 찾는다. 그리고 크롬에서 F12 키를 눌러 개발자 도구를 실행시킨다. 정보를 가져오고 싶은 영역의 HTML 태그의 클래스를 확인해야 한다.

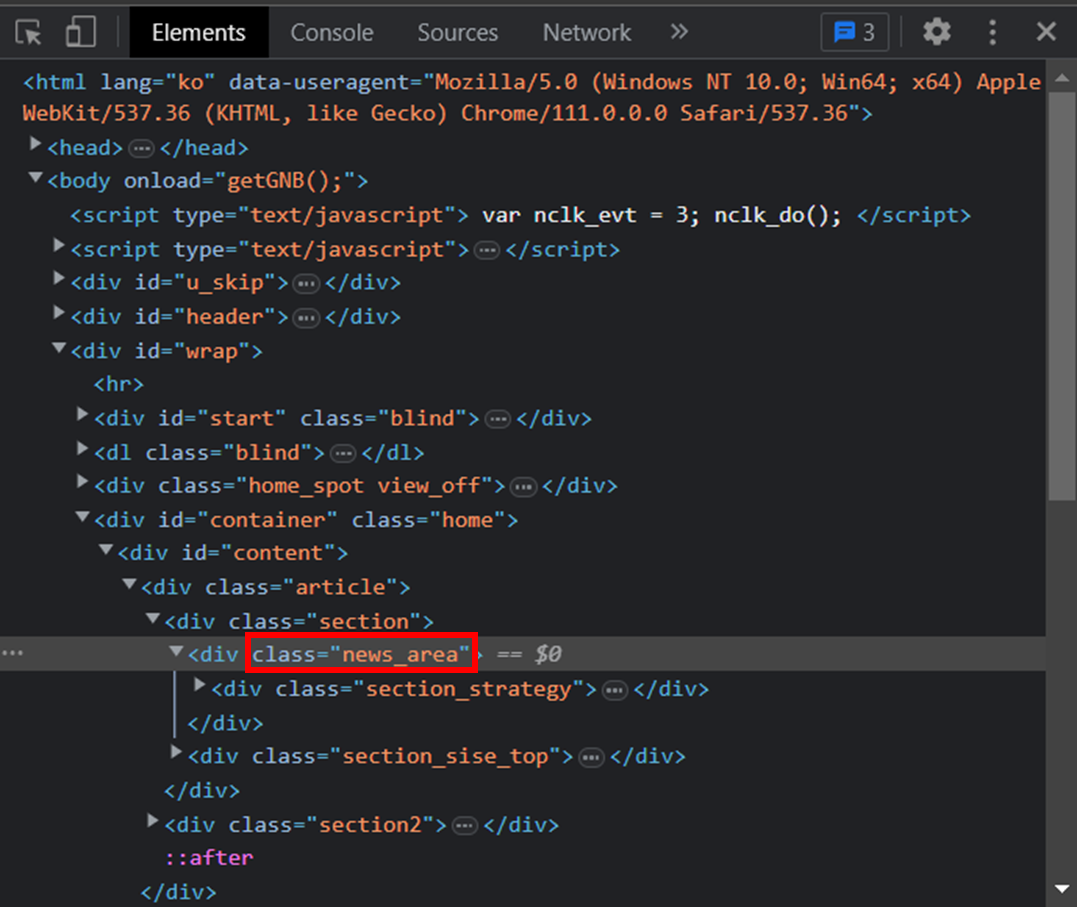
개발자 도구의 좌측 상단에 있는 아이콘을 클릭하고 본인이 스크래핑하고 싶은 영역을 클릭하면 해당 데이터를 표시하고 있는 HTML 태그를 바로 찾아준다. 해당 HTML 태그 중에서 class 명을 복사한다. 나는 네이버 증권 사이트에 접속하여 주요 뉴스란에 있는 HTML 태그의 클래스명을 복사했다. 클래스명 은 'news_area'다.
4. 코드 작성
이제 웹 크롤링을 위한 사전 작업은 모두 준비가 끝났다. 코드만 작성하면 된다.
|
1
2
3
4
5
6
7
8
9
10
|
import requests # requests 모듈 불러오기
from bs4 import BeautifulSoup # bs4 모듈 불러오기
import pandas as pd # pandas 모듈 불러오기
resp = requests.get('https://finance.naver.com/') # GET 방식 크롤링
html = resp.text # HTTP Request를 보낸 URL에서 readable한 내용을 가져옴
soup = BeautifulSoup(html, 'html.parser') # HTML 코드 형태로 구분
news = soup.select('.news_area a') # 원하는 영역의 내용 가져오기
news
|
cs |
[<a href="/news/news_read.naver?mode=mainnews&office_id=008&article_id=0004866441" onclick="clickcr(this, 'tdn.list', '008_0004866441', '0', event);">도이체방크 흔들렸지만 블라드가 한 말…다우 132p↑[뉴욕마감]</a>,
<a href="/news/news_read.naver?mode=mainnews&office_id=277&article_id=0005235863" onclick="clickcr(this, 'tdn.list', '277_0005235863', '1', event);">[유럽개장]하락 출발…英FTSE 0.73%↓</a>,
<a href="/news/news_read.naver?mode=mainnews&office_id=008&article_id=0004866331" onclick="clickcr(this, 'tdn.list', '008_0004866331', '2', event);">[Asia마감]日은 '엔고', 中·홍콩은 '차익실현'…일제히 하락</a>,
<a href="/news/news_read.naver?mode=mainnews&office_id=366&article_id=0000887877" onclick="clickcr(this, 'tdn.list', '366_0000887877', '3', event);">[마켓뷰] 코스피, 다시 하락 마감… 外人은 삼성전자만 4650억원어치 샀다</a>,
<a href="/news/news_read.naver?mode=mainnews&office_id=018&article_id=0005449211" onclick="clickcr(this, 'tdn.list', '018_0005449211', '4', event);">급락 되돌림+저가 매수…환율, 15원 이상↑ 1290원대 중반[외환마감]</a>,
<a href="/news/news_read.naver?mode=mainnews&office_id=421&article_id=0006705006" onclick="clickcr(this, 'tdn.list', '421_0006705006', '5', event);">코스피, 약보합 마감…코스닥은 반도체·게임주 훈풍에 강세[시황종합]</a>,
<a class="btn_more" href="/news/mainnews.naver" onclick="clickcr(this, 'tdn.more', '', '', event);"><em class="btn_more4"><span class="blind">주요뉴스 더보기</span></em></a>]참고로 news = soup.select('.news_area a') 문법은 여러 가지 형태가 있지만 나는 아래와 같은 구조로 사용했다.
soup.select('.클래스명 데이터를 가져올 태그명)
a 태그로 지정하지 않은 경우에는 아래처럼 해당 클래스의 내용 전체를 가져온다.
[<div class="news_area">
<div class="section_strategy">
<h2 class="h_strategy"><span>주요뉴스</span></h2>
<ul>
<li> <span><a href="/news/news_read.naver?mode=mainnews&office_id=008&article_id=0004866441" onclick="clickcr(this, 'tdn.list', '008_0004866441', '0', event);">도이체방크 흔들렸지만 블라드가 한 말…다우 132p↑[뉴욕마감]</a></span> </li>
<li> <span><a href="/news/news_read.naver?mode=mainnews&office_id=277&article_id=0005235863" onclick="clickcr(this, 'tdn.list', '277_0005235863', '1', event);">[유럽개장]하락 출발…英FTSE 0.73%↓</a></span> </li>
<li> <span><a href="/news/news_read.naver?mode=mainnews&office_id=008&article_id=0004866331" onclick="clickcr(this, 'tdn.list', '008_0004866331', '2', event);">[Asia마감]日은 '엔고', 中·홍콩은 '차익실현'…일제히 하락</a></span> </li>
<li> <span><a href="/news/news_read.naver?mode=mainnews&office_id=366&article_id=0000887877" onclick="clickcr(this, 'tdn.list', '366_0000887877', '3', event);">[마켓뷰] 코스피, 다시 하락 마감… 外人은 삼성전자만 4650억원어치 샀다</a></span> </li>
<li> <span><a href="/news/news_read.naver?mode=mainnews&office_id=018&article_id=0005449211" onclick="clickcr(this, 'tdn.list', '018_0005449211', '4', event);">급락 되돌림+저가 매수…환율, 15원 이상↑ 1290원대 중반[외환마감]</a></span> </li>
<li> <span><a href="/news/news_read.naver?mode=mainnews&office_id=421&article_id=0006705006" onclick="clickcr(this, 'tdn.list', '421_0006705006', '5', event);">코스피, 약보합 마감…코스닥은 반도체·게임주 훈풍에 강세[시황종합]</a></span> </li>
</ul>
<a class="btn_more" href="/news/mainnews.naver" onclick="clickcr(this, 'tdn.more', '', '', event);"><em class="btn_more4"><span class="blind">주요뉴스 더보기</span></em></a>
</div>
</div>]뉴스의 제목과 URL을 데이터 프레임에 넣고 싶다면 아래와 같은 코드를 작성해 볼 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import requests # requests 모듈 불러오기
from bs4 import BeautifulSoup # bs4 모듈 불러오기
import pandas as pd # pandas 모듈 불러오기
resp = requests.get('https://finance.naver.com/') # GET 방식 크롤링
html = resp.text # HTTP Request를 보낸 URL에서 readable한 내용을 가져옴
soup = BeautifulSoup(html, 'html.parser') # HTML 코드 형태로 구분
news = soup.select('.news_area a') # 원하는 영역의 내용 가져오기
title = [] # 제목 리스트 생성
url = [] # URL 리스트 생성
for n in news:
title.append(n.text)
url.append(n['href'])
df = pd.DataFrame()
df['제목'] = title
df['URL'] = url
df
|
cs |

pandas 모듈의 to_excel 함수를 이용하면 Excel 파일로 저장하는 것도 가능하다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import requests # requests 모듈 불러오기
from bs4 import BeautifulSoup # bs4 모듈 불러오기
import pandas as pd # pandas 모듈 불러오기
resp = requests.get('https://finance.naver.com/') # GET 방식 크롤링
html = resp.text # HTTP Request를 보낸 URL에서 readable한 내용을 가져옴
soup = BeautifulSoup(html, 'html.parser') # HTML 코드 형태로 구분
news = soup.select('.news_area a') # 원하는 영역의 내용 가져오기
title = [] # 제목 리스트 생성
url = [] # URL 리스트 생성
for n in news:
title.append(n.text)
url.append(n['href'])
df = pd.DataFrame()
df['제목'] = title
df['URL'] = url
df.to_excel('test.xlsx', index = False)
|
cs |


'IT > 파이썬(Python)' 카테고리의 다른 글
| 파이썬 클래스(Class), 메서드(Method), 속성(Attribute) 정의, 사용법 (0) | 2023.03.27 |
|---|---|
| 파이썬 블로그로 코드 붙여넣기 Color Scripter (0) | 2023.03.25 |
| 파이썬 문자열과 리스트 상호 변환 방법 (0) | 2023.03.19 |
| 파이썬 수치형 자료의 요약법(히스토그램, 줄기-잎 그림) (0) | 2023.03.18 |
| 파이썬 튜플의 정의, 특징 (0) | 2023.03.17 |



