
범주형 자료의 요약법은 다음 순서를 따른다.
- 각 범주에 속하는 관측값의 개수를 측정한다.
- 전체에서 차지하는 각 범주의 비율을 파악한다.
- 효율적으로 범주 간의 차이점을 비교 가능하다.
목차
1. 도수분포표
└ 1.1. 도수(Frequency)
└ 1.2. 상대도수(Relative Frequency)
2. 실습
└ 2.1. 도수 계산
└ 2.2. 상대도수 계산
1. 도수분포표
범주형 자료에서 범주와 그 범주에 대응하는 도수, 상대도수를 나열해 표로 만든 것이다. 몇 개의 범주를 기준으로 둘 것인지에 따라 다양한 도수 분포표를 만들 수 있다.
< 한 가지 범주의 도수분포표 >
pandas.crosstab(index = 범주, columns = 원하는 컬럼명)
위의 코드는 index로 설정한 범주에 해당하는 도수를 계산하여 도수분포표를 제작한다.
< 두 가지 범주의 도수분포표 >
pandas.crosstab(index = 범주, columns = 또 다른 범주)
위의 코드는 index로 설정한 범주와 columns로 설정한 범주를 모두 만족하는 도수를 계산하여 도수분포표를 제작한다.
1.1. 도수(Frequency)
각 범주에 속하는 관측값의 개수다.
데이터프레임[범주].value_counts()
1.2. 상대도수(Relative Frequency)
도수를 자료의 전체 개수로 나눈 비율을 뜻한다.
데이터프레임[범주].value_counts(normalize=True)
2. 실습
위와 같은 데이터가 있다. 도수, 상대도수, 도수분포표를 만드는 실습을 해보도록 하자.
2.1. 도수 계산
먼저 pd_read_csv 코드를 통해 엑셀 파일에 있는 내용을 data라는 변수에 입력한다. 그러고 나서 value_counts()로 Name 열의 도수를 계산한다. 결과를 확인해 보면 포도가 가장 많은 도수를 가지고 있는 것을 알 수 있다.
2.2. 상대 도수 계산
value_counts() 대신 value_counts(normalize=True) 코드를 입력하면 상대 도수를 계산해 준다. 포도(grape)의 도수는 3이었고 가장 많은 빈도수를 가지고 있었으므로 상대 도수 또한 가장 높은 비율을 나타내는 것을 확인할 수 있다.
2.3. 도수분포표 만들기
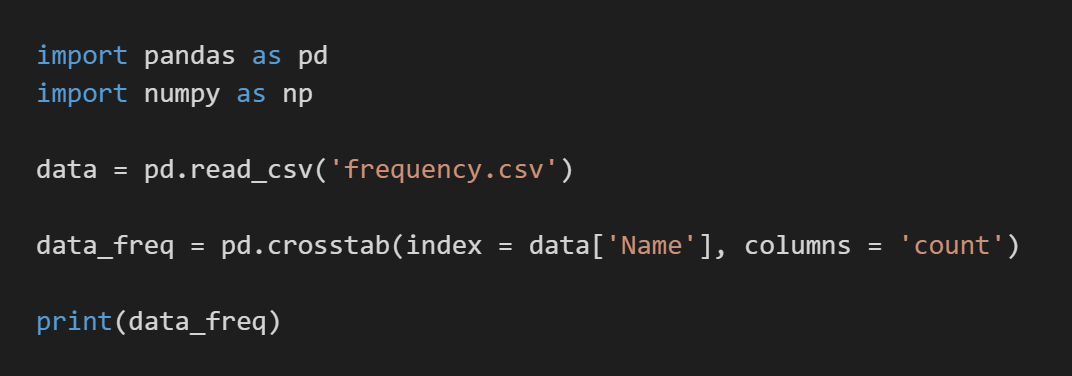
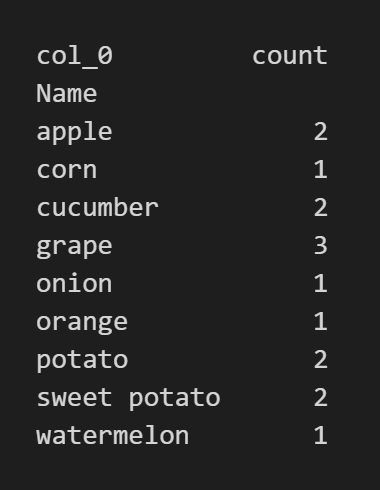
pd.crosstab() 코드는 도수분포표를 작성해 준다. index 값에 과일들의 이름이 적혀있는 'Name' 열을 선택했다. 그리고 열(column) 이름은 'count'로 설정했다. 이 도수분포표는 하나의 범주만 가지고 있는 것이다.

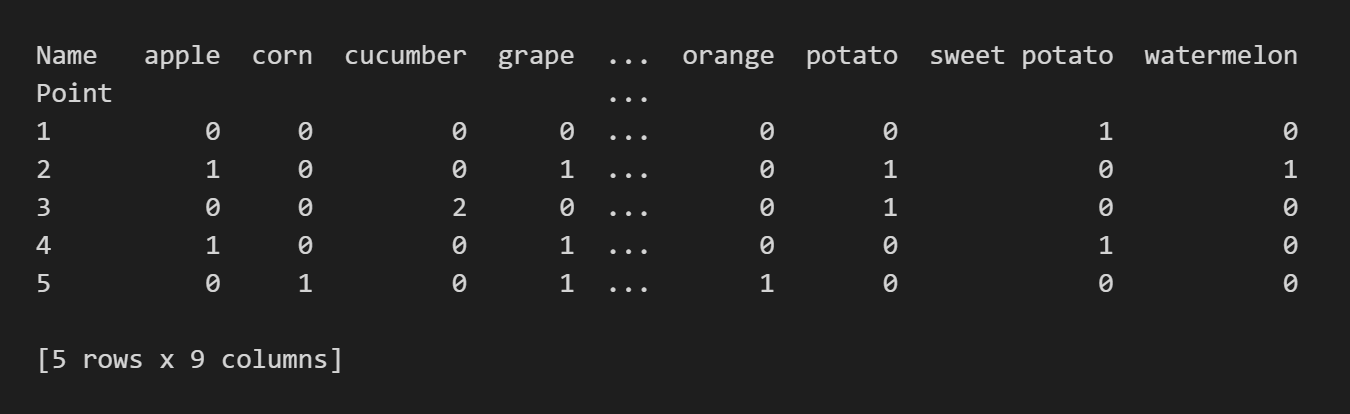
이 형태는 두 가지 범주를 가지고 있는 도수분포표다.
'IT > 파이썬(Python)' 카테고리의 다른 글
| 파이썬 거듭제곱 연산자(**) 사용법 (0) | 2023.03.14 |
|---|---|
| 파이썬 범주형 자료의 요약법(그래프) (0) | 2023.03.13 |
| 파이썬 자료의 구분(수치형, 범주형 자료) (0) | 2023.03.11 |
| 파이썬 예외처리 하는 방법(try, except) (0) | 2023.03.04 |
| 파이썬 문자열 숫자로 바꾸기 (0) | 2023.03.03 |



